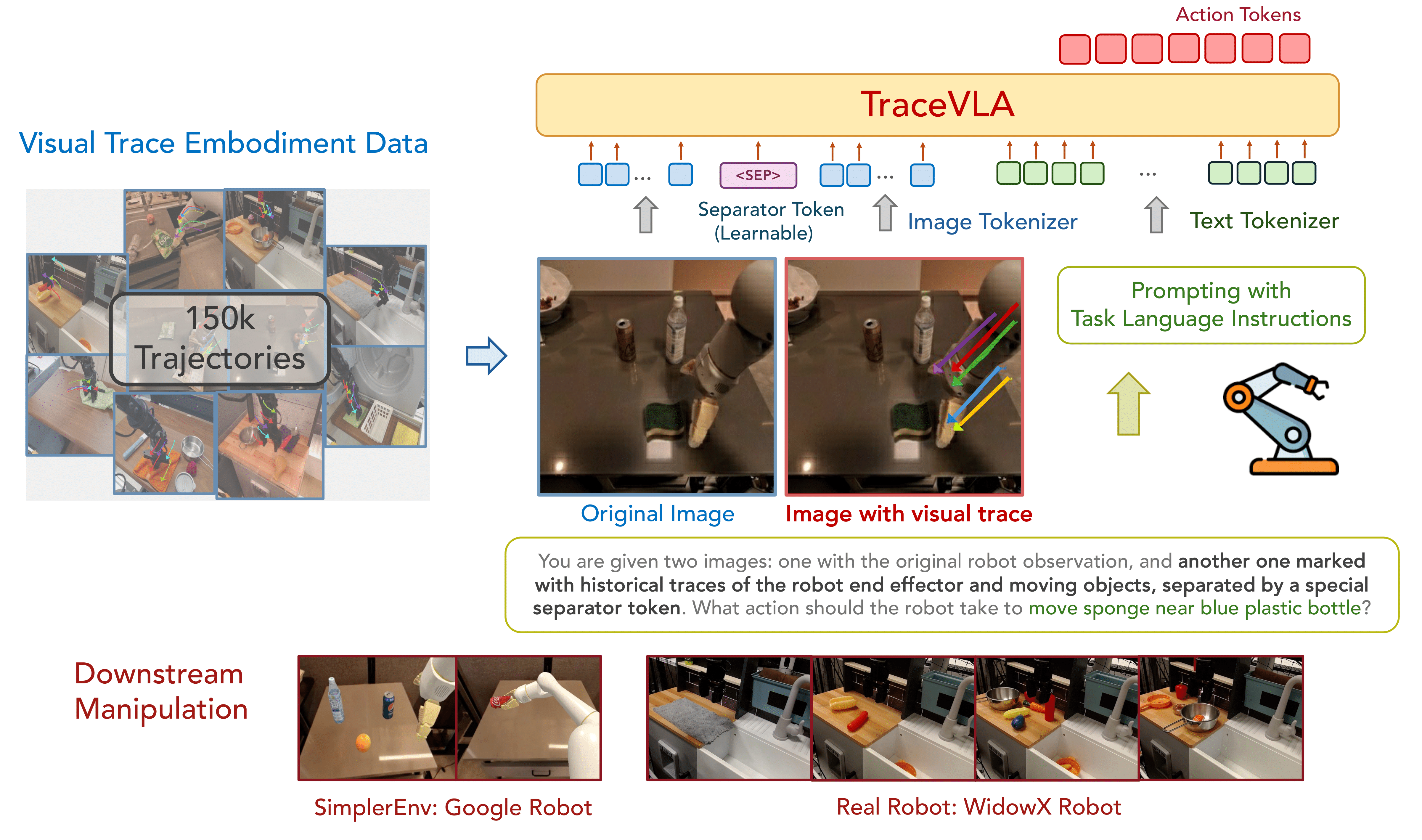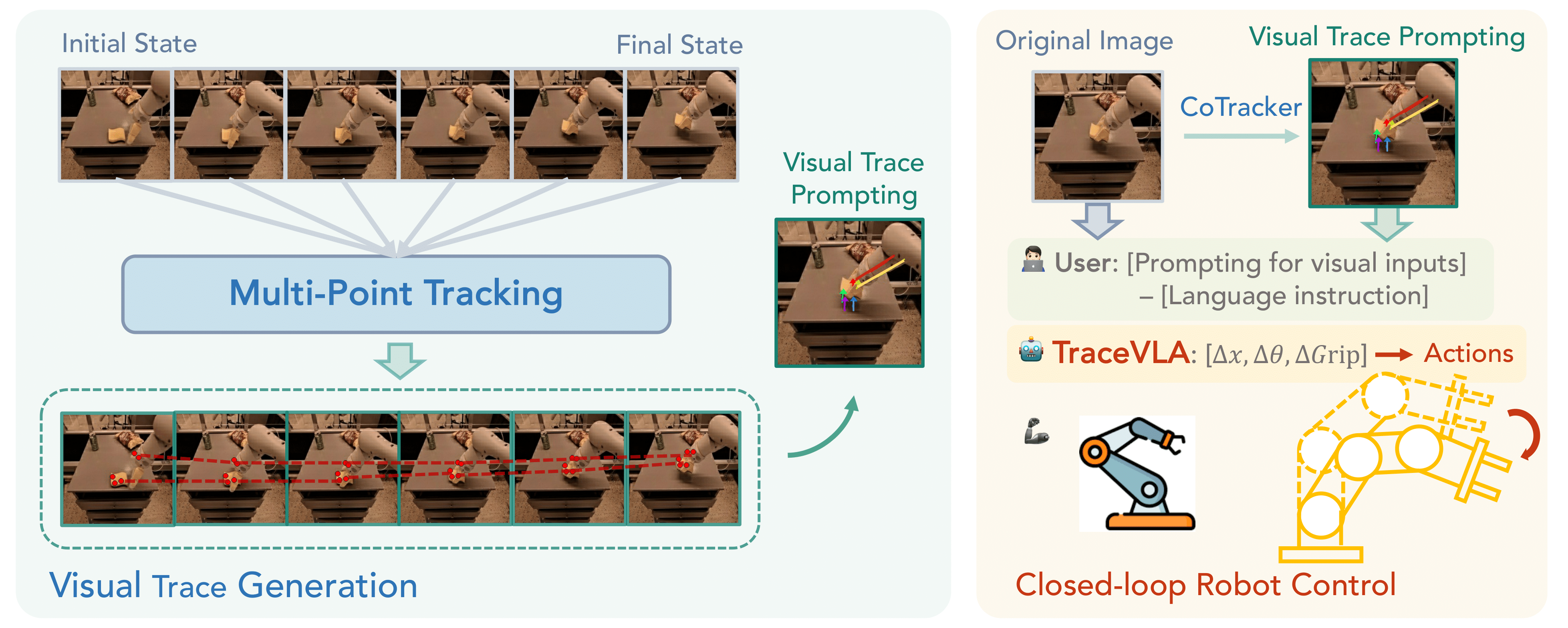
Given a sequence of historical image observations, we first use Co-tracker to extract dense point trajectories and keep active point trajectories with significant movement. We then overlay active point trajectories on the robot’s initial observation frame as visual trace prompting and feed both the image overlaid with visual traces and the original image into VLA as model input.
Below are videos of TraceVLA and OpenVLA on physical WidowX-250 robot manipulation tasks with different manipulation skills and objects. (Videos are sped up by 2.5x.)
TraceVLA masters soft object manipulation, pick-and-place operations, and object movement, demonstrating reliable performance in both in-distribution and out-of-distribution generalization tasks.
(In-Distribution)
(Out-of-Distribution: Unseen Task)
(Out-of-Distribution: Unseen Task)
(Out-of-Distribution: Unseen Object)
(Out-of-Distribution: Unseen Task)
(Out-of-Distribution: Distracting Object, Inverse Motion)
We design 8 real-world robot tasks with different manipulation skills and objects and include unseen tasks involving novel objects, goals, and language instructions for evaluating generalization in real robot settings.
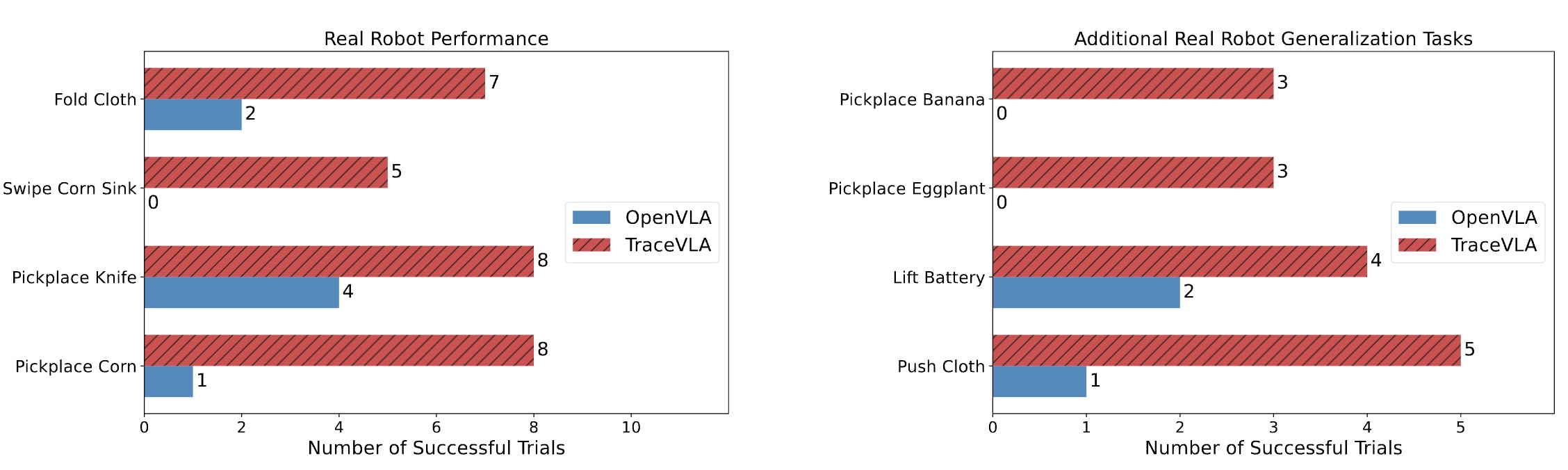
TraceVLA consistently outperforms OpenVLA across diverse tasks including soft object manipulation, pick-and-place operations, and object movement and demonstrates superior generalization
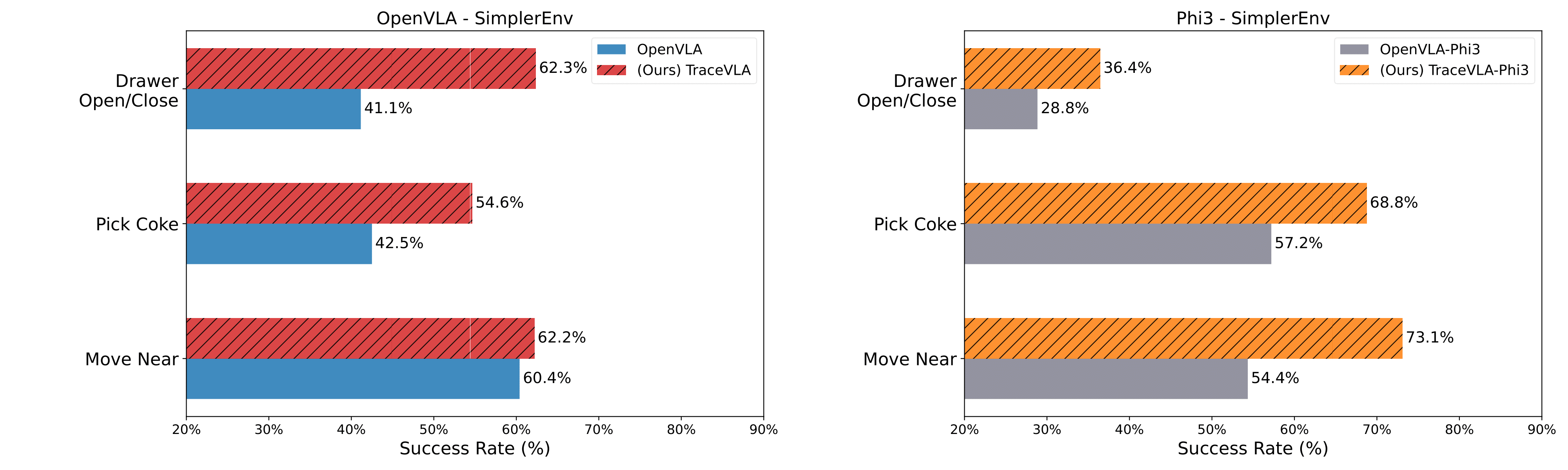
TraceVLA consistently outperforms OpenVLA across various tasks and evaluation metrics in the SimplerEnv Google robot tasks. The improvements are evident in both the full-scale 7B models (TraceVLA vs OpenVLA) and their 4B versions (TraceVLA-Phi3 vs OpenVLA-Phi3).
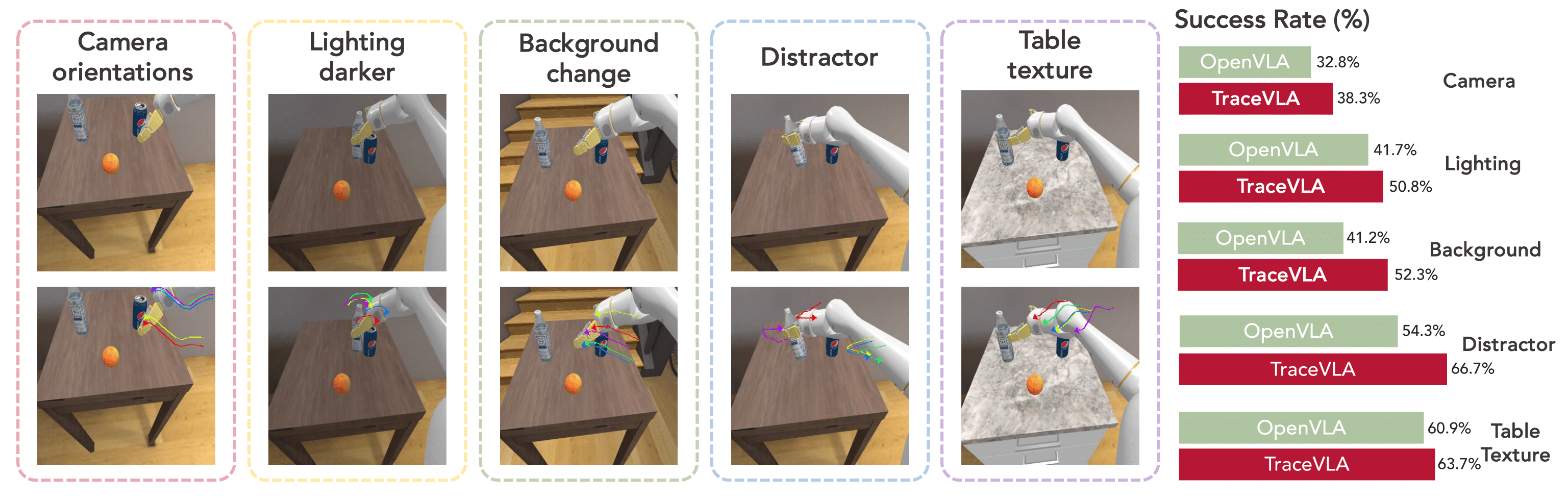
Environmental Variant Aggregation: TraceVLA shows substantial enhancements under camera orientation changes, distractor presence, and background alterations, with an average improvement exceeding 20% in these categories.
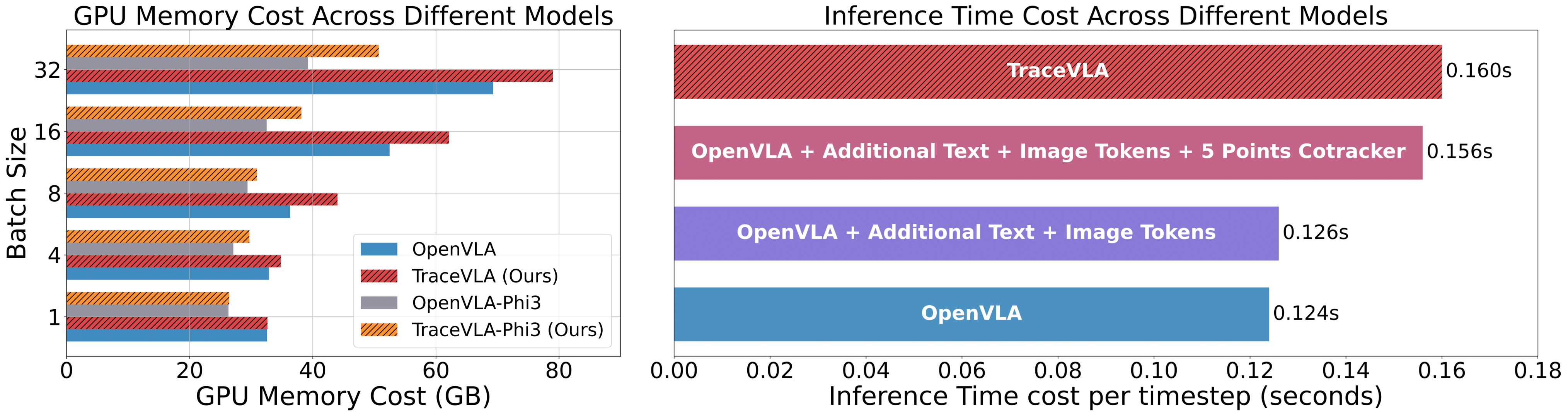
TraceVLA's memory overhead is manageable at less than 10GB when using 8 H100 GPUs, with the difference decreasing at smaller batch sizes. In terms of speed, the model introduces three main components during inference: image/text tokens (0.002s), CoTracker tracking (0.03s), and dense point tracking (0.004s) per timestep. These additional computational costs remain relatively small and well-optimized due to GPU attention optimization.
@article{zheng2024tracevla,
title={TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies},
author={Zheng, Ruijie and Liang, Yongyuan and Huang, Shuaiyi and Gao, Jianfeng and Daum{\'e} III, Hal and Kolobov, Andrey and Huang, Furong and Yang, Jianwei},
journal={arXiv preprint arXiv:2412.10345},
year={2024}
}